Trabalhando com Ruby e arquivos no S3


Como gravar arquivos no S3 utilizando Ruby.
O Amazon S3 é um serviço de armazenamento de objetos altamente redundante e com um custo/benefício excepcional.
em um ambiente elástico, é fundamental ter um repositório de arquivos compartilhado. Antigamente este repositório geralmente era um NFS ou um filesystem distribuído, como GFS ou até mesmo o DRBD. Quando um desenvolvedor precisava disso, ele dependia de algum sysadmin para implementar e manter este serviço. No fim, além de ser uma solução mais cara que o S3, é também mais trabalhosa para implementar e manter.
Com o S3, desenvolvedores podem armazenar arquivos no S3 sem precisarem se preocupar com a replicação e alta disponibilidade. Isso porque o S3 é um serviço gerenciado pela AWS que fornece um SLA de durabilidade de onze noves: 99,999999999%. Basta pouquíssimas linhas de código para que tenha um bucket pronto para armazenar uma infinidade de arquivos.
Neste artigo exemplificaremos como criar um bucket, salvar, deletar e conceder permissões em um arquivo. usaremos a linguagem Ruby pela praticidade dela.
Conceitos Fundamentais
É importante saber que, apesar de ser possível configurar as credenciais de acesso dentro do seu código, por questões óbvias de segurança isso não é recomendável. Também não é recomendável que você configure suas credenciais dentro do sistema operacional, visto que elas ficarão expostas para qualquer um que tenha acesso ao servidor.
A maneira recomendada de conceder acesso das suas instâncias ao recurso do S3 é através de Roles do IAM. Utilizando Roles é possível permitir que determinadas instâncias tenham acesso a recursos específicos do S3. Com isso suas credenciais não ficam chumbadas no código ou em um arquivo de configuração.
Criando Role
O primeiro passo que faremos será criar uma Role chamada EC2toS3 que concederá acesso total ao S3 para instâncias que iniciarem com esta Role.
Para isso, acesse a console da AWS, vá em IAM e clique em Roles, Create Role.
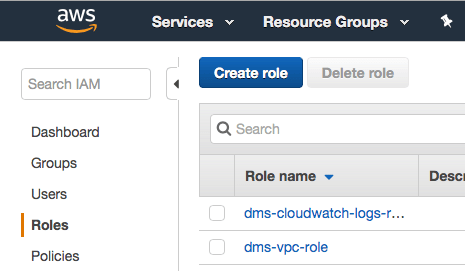
Em AWS Service, selecione EC2.
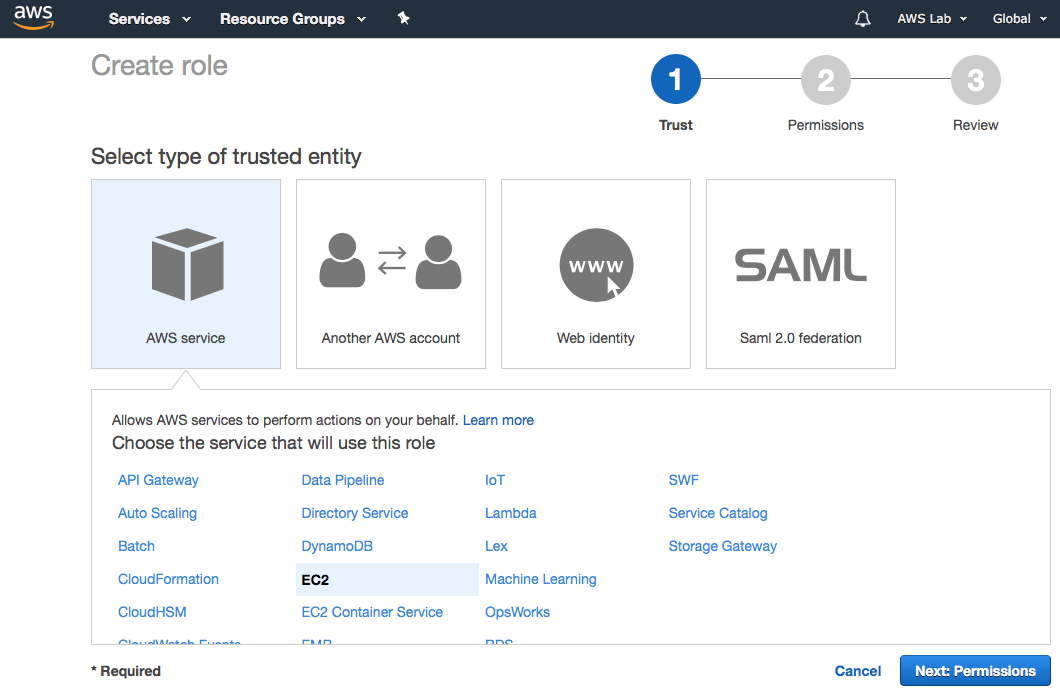
Em Select your use case, selecione EC2 novamente e clique em Next:Permissions.
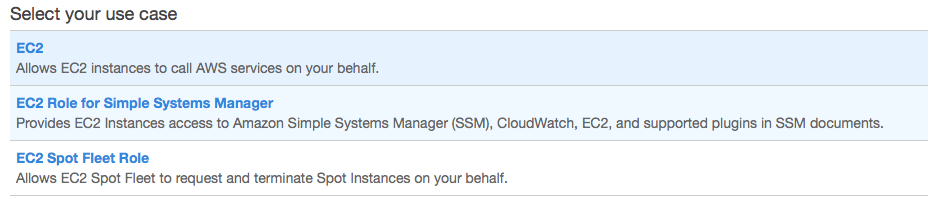
Na próxima tela você selecionará qual policy será atribuída à instância. Para nossa necessidade, selecione AmazonS3FullAccess. Se desejar, você pode criar uma policy customizada com permissões mais restritivas. Clique em Next.

Especifique o nome da Role e clique em Create Role.
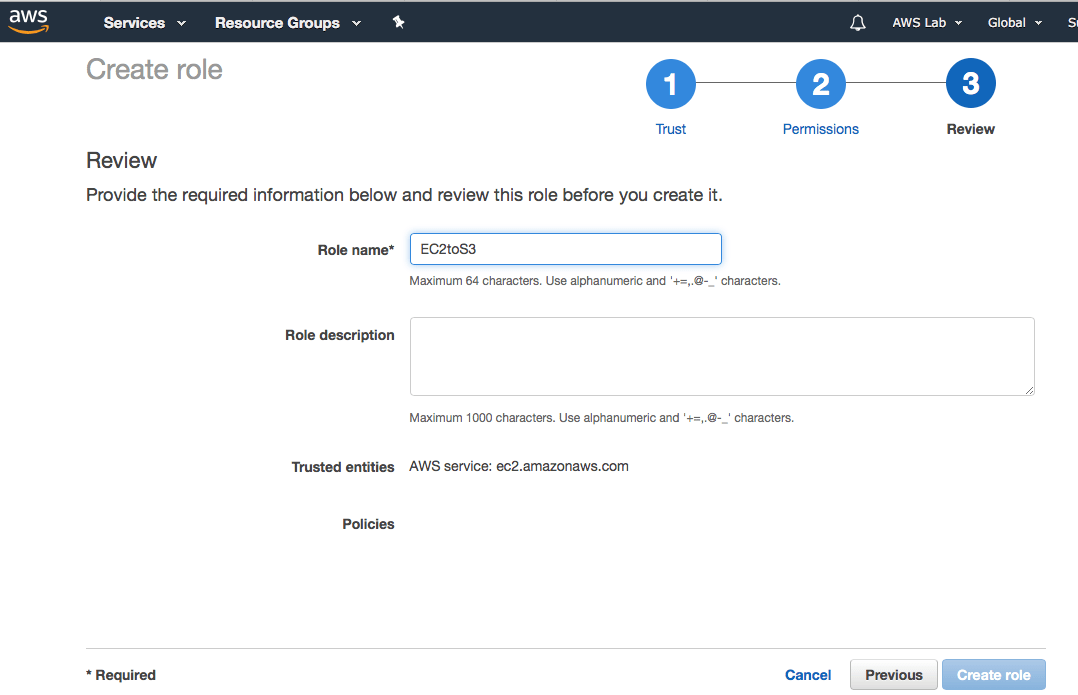
Pronto, sua Role para que instâncias EC2 possam trabalhar com o S3 está criada!
Aplicando a Role em uma instâncias EC2
Agora que temos a Role criada, vamos aplica-la em uma instância Linux que usaremos para rodar nosso código em Ruby.
Não vou explicar como lançar uma instância na AWS porque entendo que isso deve ser um pré-requisito para quem quer trabalhar com o S3 e EC2. Vou me limitar a explicar as opções para aplicar a role na instância.
No lançamento da instância
Durante o Wizard de lançamento de instância temos a opção de anexar uma Role, conforme imagem abaixo.
Em uma instância já em execução
Se você quiser aplicar a Role para uma instância já em execução, vá na Console do EC2, selecione a instância, clique em Actions, Instance Settings e Attach/Replace IAM Role.
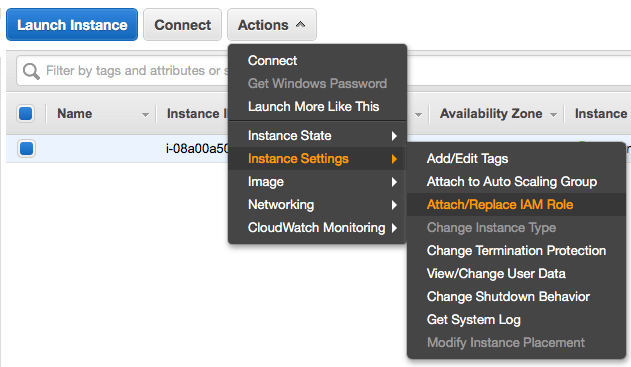
Selecione a Role criada e clique em OK.
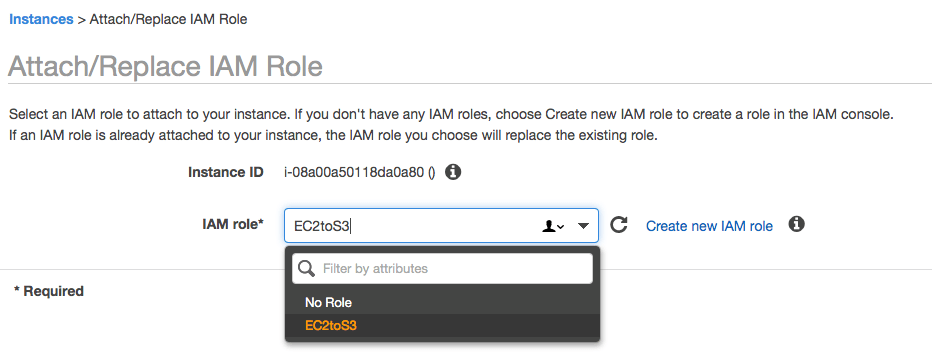
Agora você já tem uma instância autorizada a trabalhar com o S3!
Instalando a SDK da AWS para Ruby
Você pode acessar a instância e executar os comandos abaixo ou, se estiver lançando uma nova instância, inserir estes comando no userdata para que sejam executados no lançamento.
sudo yum install -y rubygem20-aws-sdk
gem install aws-sdk-s3
Criando um Bucket
Vamos criar um arquivo chamado criabucket.rb com o conteúdo abaixo.
require ‘aws-sdk-s3’
#Variavel que define o nome do bucket que será criado
nomebucket = ‘nimborocks-bucket-teste01’
s3 = Aws::S3::Resource.new(region: ‘us-west-1’)
s3.create_bucket(bucket: nomebucket)
Após isso, vamos rodar:
ruby criabucket.rb
Para confirmar que seu bucket foi criado, navegue até a console do S3 e verifique.
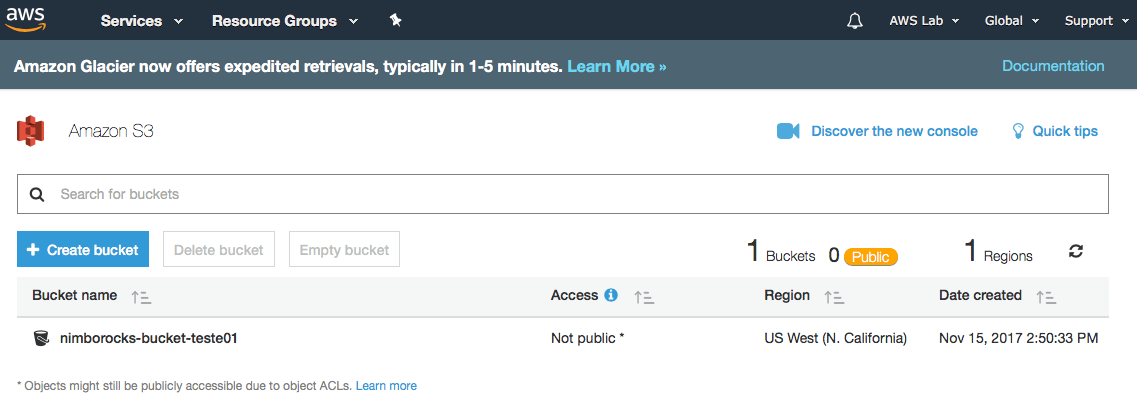
Salvando arquivo no S3
Vamos agora criar um novo arquivo com o código para fazer upload de um arquivo .pdf para o S3.
require ‘aws-sdk-s3’
# variavel com o nome do bucket
nomebucket = ‘nimborocks-bucket-teste01’
# variavel com o nome do arquivo que sera criado
nomearquivo = ‘meuarquivo01.pdf’
# variavel com o caminho do arquivo para upload
origem = ‘/home/ec2-user/fontes/arquivo.pdf’
# Upload de arquivo aplicando a ACL de public-read
s3 = Aws::S3::Resource.new(region: ‘us-west-1′)
obj = s3.bucket(nomebucket).object(nomearquivo)
obj.upload_file(origem, acl:’public-read’)
Salve o arquivo com nome de uplad.rb e execute:
ruby upload.rb
Pronto! Seu arquivo está salvo no S3!
Quer conferir? Acesse a console do S3 e navegue dentro do bucket recém criado.
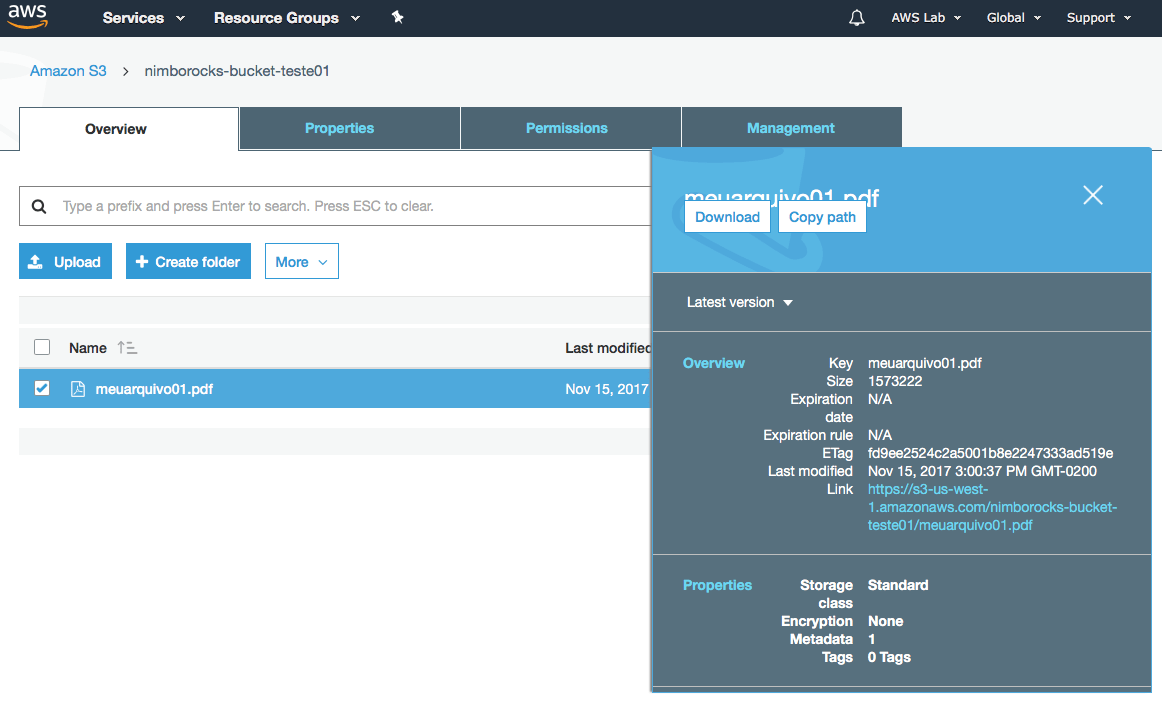
Você poderá acessar diretamente o arquivo através da URL: https://s3-us-west-1.amazonaws.com/nimborocks-bucket-teste01/meuarquivo01.pdf
Repare que no upload passamos o parâmetro acl:’public-read’. Sem este parâmetro o arquivo é salvo mas sem qualquer permissão de acesso. Também é possível criar ACLs mais restritivas se necessário.
Difícil? Não, né!
Deletando arquivo no S3
E para deletar um arquivo?
require ‘aws-sdk-s3’
# variavel com o nome do bucket
nomebucket = ‘nimborocks-bucket-teste01’
# variavel com o nome do arquivo que sera criado
nomearquivo = ‘meuarquivo01.pdf’
# Para deletar um arquivo
obj = s3.bucket(nomebucket).object(nomearquivo)
obj.delete
Conclusão
Com uma pequena curva de aprendizagem desenvolvedores podem começar a usar o S3 como repositório compartilhado de arquivos. O S3 é uma solução mais eficiente do que o NFS para compartilhar arquivos entre instâncias.